

5·
14 hours agoSorry, I couldn’t quite get the feeling you described. It’s partially because I have seen that before and partially because it still looks old and the sound quality was reminiscent of a cylinder phonograph.
Good try though. ;)
Sorry, I couldn’t quite get the feeling you described. It’s partially because I have seen that before and partially because it still looks old and the sound quality was reminiscent of a cylinder phonograph.
Good try though. ;)
I have been working through my “must watch” list with my teenage daughter recently. While all the movies are absolutely new to her, that hasn’t stopped the occasional snickering about how “old” some of the stuff is. (And honestly, I can’t disagree. I had a few “ah fuck I’m old” moments rewatching Predator and Blade Runner recently.)
So, in spirit, I 100% agree with you. In reality, nobody can quite escape how old some movies actually feel.

Something about this post title screams dirty poem.

AIDS doesn’t exist in Russia and is just CIA propaganda.(Someone from ml probably.)
Look on the bright side! Blucifer killed its creator, so no other airport can ever be cursed with this “art”.
Denver on a slow day, which is rare, and only for the weird airport lore, gargoyles and also Blucifer, the demon mustang with big ole blue balls and a huge asshole. The trams are really good, but everything else kinda sucks.


A potato is much happier as vodka as indicated by common potato lifecycle charts.
Doesn’t need to be in the same band due to harmonics and power. If you keep splitting the 11m band (CB) into “fractional-frequencies”, you are going to get a cross-over somehow, especially if the fundamental is at super-high power.
Using a piano as an example, if you play a C2 at 62.41Hz it still expresses harmonics at C3 (130.81Hz), G3 (196.22Hz) and C4 (261.63Hz) and at least in theory, to infinity and beyond! Each harmonic away from the fundamental will be expressed in decreasing levels of power. (It’s like 1/3 power per, I think. The proper math is out there though.)
I am curious what your intentions were for a potato that you planted that wasn’t supposed to grow?
I ask because it might help formulate a plan if we can determine your intentions and expectations.
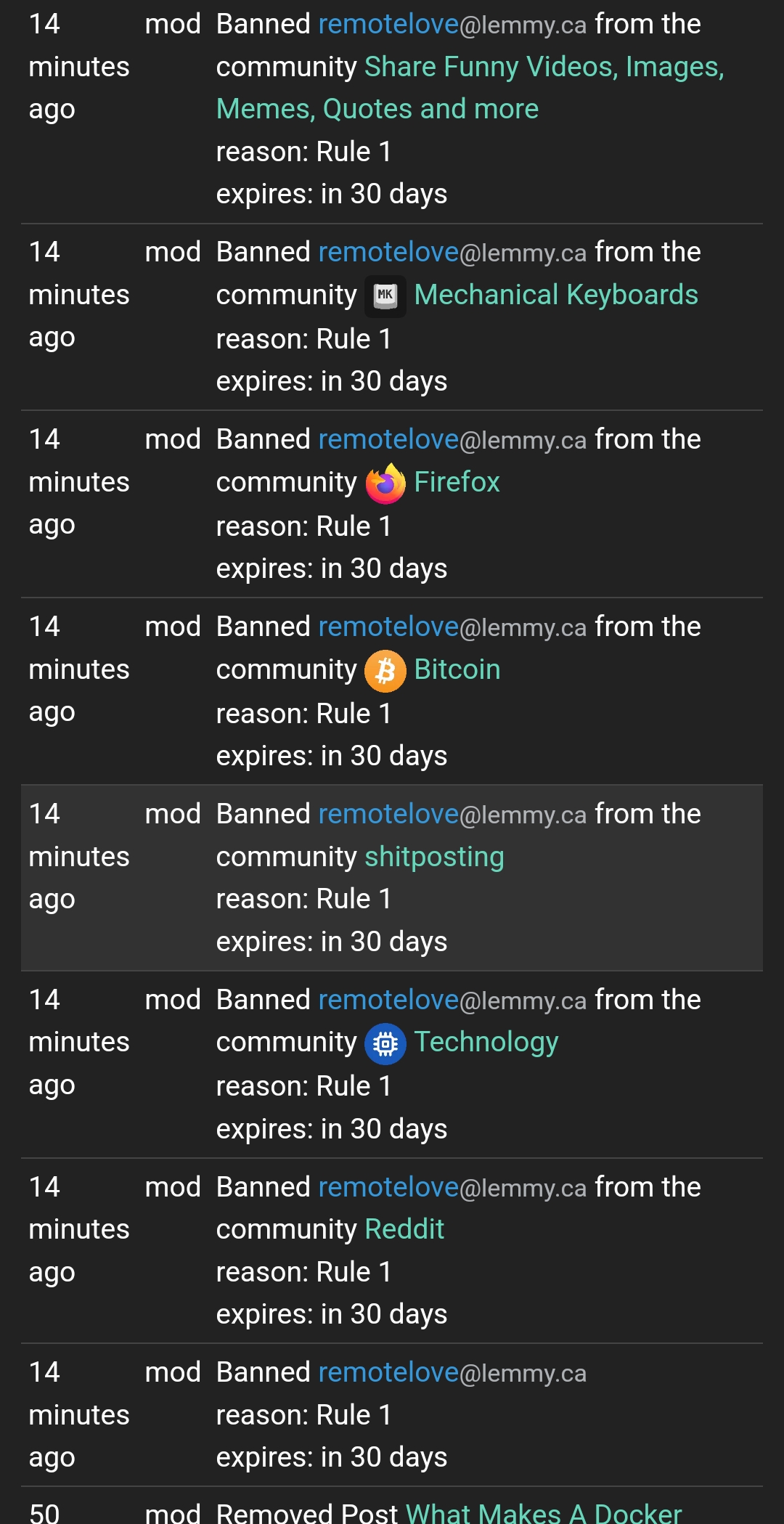
I can still report posts on communities that I wasn’t explicitly banned from, which is just super weird. A proper ban prevents reports, at least.
TBH, I don’t care about the bans, but the Lemmy behavior is something to take note of for other admins and mods.
It’s also super inefficient. Comrade dipshit missed quite a few communities so it seems he can only ban based on communities I have commented in at one time or another.
You would think that the free speech leader of the world could write a better mechanism to erase dissent.
(sorry to add even more; I just made another comment about this and I am familiar with most of these concepts.)
Actually, that would be much easier. TV stations back then mostly received shows via satellite dish. Pointing a low power directional antenna directly at the dish’s LNB would work great. Satellite transmissions weren’t strong and were rarely encrypted back then so that would theoretically be super easy if you knew your RF and deep RF knowledge was much more common place +30 years ago.
I am not sure if they used point-to-point microwave antennas back then for TV, but it would be the same concept. (Microwave antennas are typically the round, cylindrical looking, covered antennas we see all over the place today.)
It would require as much, or more, power to drown out a TV broadcast signal at the source. I believe many of the old towers were 200kW-1000kW so it would have taken one hell of a pirate signal if interfering close to the main source. However, RF follows the same principle as light using the inverse square law so the further you get from the primary transmitter, the signal quickly becomes exponentially weaker for any receiver.
If you had a TV transmitter on a small hill that is a fair distance away from the target audience, like many were, splitting the distance with a directional antenna wouldn’t require nearly as much power from the pirate signal to overtake the original transmission.
If I wanted, I could interfere with ham radio signals with as little as a watt of power (in my immediate local area) even though people might be communicating through a ham radio repeater that transmits at a couple of thousand watts that is many miles away. (It’s actually a permitted emergency technique to “break into” active conversations. Actually, other ham radio operators are familiar with what interference sounds like, even for signals that can’t fully overtake a transmission. It’s customary to stop the conversation if detected and wait for the “break”.)
Lulz. I was instance banned by the head comrade himself, so it fits.

Right-wing politics basically requires one or more sub-cultutes to demonize. It’s hate and blame politics, pure and simple.
As long as the politicians have someone to wag a finger at and blame for all problems, it rallies their supporters. Nazis had the Jews, Republicans have everyone else that they declare different.

Just by looking at it, this model should scale easily in the slicer. (Scale up by 21.5% if my math is correct.) It may look odd, but even scaling up one axis (Y) may work too.
Here is the follow-up post on the joke, btw.
Wustite, ferrous oxide, is black. FeO.
Typical rust, usually found as hematite, is Fe2O3 and is red/brown. Also an iron oxide.
Magnetite is also another black iron oxide, Fe3O4.
There are quite a few other flavors of iron and oxygen too.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I actually like the audio. (I’ll leverage faux tape recording effects and plate reverb on occasion with music I write.)
And honestly, it was kinda refreshing to watch Charlie Chaplain again.